


Jag deltog under hösten och vintern i ÅA:s utbildning “Det goda akademiska ledarskapet”. Sista tillfället hölls förra veckan på tisdagen (6.2.2024). Bland de olika temata som behandlades upplevde jag som mests intressant diskussionen av behovet av kompetensutveckling och omskolning (reskilling and upskilling) under perioden 2023-27. Tabellen nedan visar att olika typer av kompetenser och hur deras ranking har ändrats från senaste upplaga av rapporten. Iögonfallande är att AI och big data har flytta upp till 3. viktigaste utvecklingsbehov för personalen i företag. Det som jag också upplever som intressant är att AI och big data är den enda tekniska kompetensen som specifikt behövs, största delen av de andra behoven är vad ja skulle lite förenklat skulle klassa under personliga, sociala eller samhälleliga förmågor. Detta fick mig att börja fundera på vad de konkreta AI och big data kompetenserna är som skulle behövas. Frågan är för mig viktig, iom. att jag undervisar kursen “introduktion till artificiell intelligens”, som är obligatorisk för alla IT studerande men som också avläggs av studerande från andra fakulteter samt Fitech-studerande. Min tanke med kursen är att den skulle vara mera allmänbildande än teknisk, dvs, målet är mera att ge en överblick över vad artificiell intelligens är och var den kan tillämpas än hur den kan tillämpas.
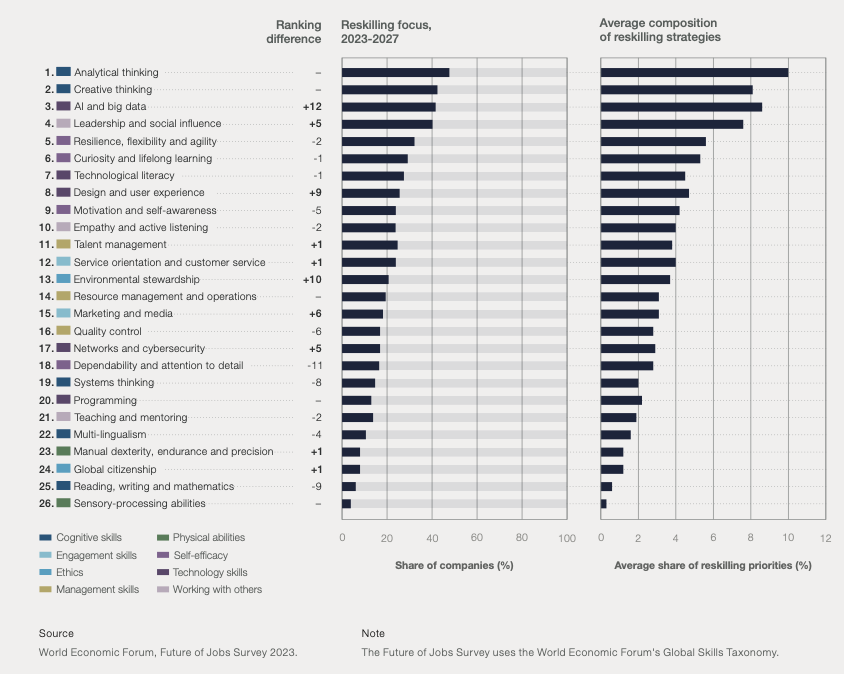
WEF:s rapport använder begreppet “AI and big data”. Inom ett område som just nu fyller rubrikerna och som redan starkt drivits nationellt via bla statens AuroraAI program, Arbets- och näringsministeriets AI 4.0, Business Finlands AI Business program, som utvecklat slogans som “Data is the new Oil”1, och där just nu ett finskt företag drivet av en ÅA alumni tar stora steg framåt inom bla. generativ AI (Silo.AI), frågar jag mig ändå vad dom här baskunskaperna är som borde läras ut. Inom ett område som utvecklas hela tiden borde man i stället för att läras sig om den nyaste teknologin, förstå fundamenten så att man ta till sig den nya teknologi utvecklingen.
Mycket av det som kan ses ingå under rubriken Big Data och som sloganen “Data is the new Oil” refererar till är användningsområden som redan tidigare använt sig av data. Främst talar vi om olika typer av optimeringar inom företag och industri. Den stora förändringarna är att vi nu faktiskt har tillgång till stora mängder data via sensorer och informationskällor på internet, och vi har tillgång till den beräkningskapacitet som behövs för att behandla det här datat med algoritmer. Själva grundmetoderna (t.ex. olika typer av klusterering) har varit kända sedan länge. Den enda egentliga nya teoretiska utvecklingen har varit djupinlärning (dvs. användning av mera komplicerade neurala nätverk, och träning av dem via “gradient descent” algoritmen, som den också är en standard optimeringsalgoritm). Jag är inte mera alls överraskad över nyheter som t.ex. berättar att man nu från cell-bilder kan förutsäga utvecklingen av cancer. Det kreativa är att få tag på datat och definiera kategoriseringen av detta data så att vi sen kan mata denna åt en träningsalgoritm.
Det verkligen nya upplever jag är de som kallas för Generativ AI, dvs tekniker som nu kommersialiseras som Chat-GPT, Co-Pilot (som vi vid ÅA ha tillgång till via vårt avtal med Microsft), Googles Gemini, mm. Jag som jobbat med behandling av naturligt språk på 1980-talet kunde inte i mina drömmar ens tänka mig att något så utvecklat som Chat-GPT et co någonsin skulle se dagsljuset. De tekniker som då användes kunde helt enkelt inte praktiskt skalas upp till att beskriva hela språket. Det som Generativ AI gör är att man inte har en explicit beskrivning av språket, dess regler, dess ordförråd med betydelser, utan man helt enkelt har en statistisk approximation på vilket ord som brukar följa på ett annat ord. När man tar in tillräckligt med språkligt material, bildas alltså en “stokastisk papegoja”2, som alltså repeterar vad den lärt sig. Det som är fascinerande är att dessa verktyg faktiskt är så bra på föra en dialog. Och det är därför som jag tycker att vi borde mycket bättre förstå vissa grundprinciper som gäller. Jag skulle vilja kalla detta AI läskunnighet, på samma sett som man talar om Medialäskunnighet, mm.
Generativ AI utvecklas av företag. Och då utvecklingskostnaderna är mycket höga, ligger det i företagens intresse att ge en så positiv bild av utvecklingen som möjligt. Till detta hör bla att på ganska dubiösa sätt spela ner riskerna med AI3. Eller att marknadsföra mekaniskt kombinerande som förståelse4,5. Allt för att sälja teknologin bättre. Därför upplever jag att det är viktigt att man se genom den anstormning av hajp som vi utsätts för. För att kunna göra detta borde vi därför förstå vissa grundproblem som generativ AI har.
Generativ AI utmanar vårt förståelse av begrepp som intelligens och kunskap. På samma sätt som man under de senaste seklen på olika sätt automatiserat bort fysiskt arbete inom produktion, börjar Generativ AI automatisera visst tankearbete som vi tidigare upplevt som centrala för kunskapsarbete. Dvs. vad är mervärdet av att komma ihåg en massa detaljer om dessa snabbt kan hittas via ett AI verktyg? Men problemet ligger i att för att vi kan lita på att svaren från en AI borde vi kunna lita på att den har
- All kunskap kring området,
- den kan se skillnader på olika tolkningar av fenomenet så att den inte gör egna
bedömningar, - den kan svara när den inte vet,
- den gör inga egna härledningar, mm.
Alla dessa punkter är lärandemål för akademisk utbildning. Och just nu finns inga metoder för att säkerställa att en Generativ AI klarar av att uppfylla den här typen av krav. Som Datavetare vill jag hävda att det inte finns metoder för att bevisa att en AI uppfyller dessa krav, utan i syvende och sist måste vår användning av Generativ AI bygga på förtroende till det företag som bygger produkten, och då inger exemplen ovan inte riktigt tillit.
Jag ser dock också 2 andra dimensioner som det är viktigt att vara medveten om, det ekologiska och det politiska.
Generativ AI har ett stort koldioxidavtryck. En dator är egentligen en energi-omvandlare. Vi kör in elektricitet och den transformeras till värme. Som biprodukt får vi beräkningar. Energiförbrukningen och den producerade spillvärmen börja bli ett allt större problem för
utvecklingen. T.ex. Microsoft har byggt ett stort datacenter i Esbo som använder 200MW i el. Ett annat sätt att tänka är att man i Esbo har byggt ett 200MW värmekraftverk. Inom huvudstadsregionen är 200MW i värme inte i sig ett problem då man kan köra in spillvärmen i fjärrvärmesystemet, men på många andra ställen har man inte denna
möjlighet. Jag tippar att största delen av belastning i Esbo består av traditionell Office 365 program, men Microsoft erbjuder också olika typer av AI tjänster som företag börjar ta i bruk via PowerBI produkten. AI behöver speciella processorer, som kallas grafikprocessorer för dom utvecklades ursprungligen för spelbruk. En grafikprocessor kan göra matrismultiplikationer snabbt, och är därför den centrala komponenten i
alla AI om man vill har vettiga responstider. Men en GPU (grafikprosesser) har en flerfaldig energiförbrukning jämfört med en traditionell processor. En modern laptop (mac eller pc) har en effektförbrukning på 30-70 watt. Tidigare var det enkelt att förklara vad det här betyder för det gäller bara att jämföra värmen i en 30W lampa med en 70W lampa. 70W är hett, och 100W är ännu hetare. Nya NVidias H100 GPU som bla används av OpenAI har en effekt på 700W. Nvidia estimera att man kommer att sälja 1-2 miljoner av dessa processorer under 2024, och att den total energiförbrukningen kommer att ligga mellan städer som Phoenix och Houston6.
Men nu kommer det politiska in i spelet. Silicon Valley är hemvist för en hel del extrema ideologier, som kan sammanfattas under akronymen TESCREAL7. Till dessa ideologier hör Accelerationism8, som förespråkar en starkt gärna hyper-exponentiell teknologisk utvecklings om kommer att leda till en tekno-utopi, som styrs av en välvillig diktator som är en AI. Och det är egentligen detta som driver Sam Altman (vd. för openAI), som planerar att köpa 10miljoner GPU:n av Nvidia för att skapa en AGI en artificiell generell intelligens9. Med den här mängden beräkningskapacitet som alltså betyder ett energibehov på 7TW med tillhörande extra energibehov för kylning, räknar han att openAI har tillräckligt med kapacitet för att skapa en AGI.
Om vi bortser från den tekniska utmaningen, bygga ihop det hela och bli av med värmen, finns en mera fundamental fråga. Är det möjligt att skapa en AGI? Det hela är också en fråga om definition, dvs. vad menas egentligen med intelligens. Själv intresserar mig frågan ur ett datavetenskapligt perspektiv, vad är en AGI:s beräkningsförmåga? Dvs, finns det frågor som den inte kan ge svar på? Kan vi karakterisera dessa frågor i mera abstrakta generiska termer? Vi vet ju redan att en Generativ AI inte kan räkna, därför att det inte går att göra induktion med statistik, och egentligen baserar sig all matematik på induktion i någon form. Men finns det andra matematiska egenskaper med vilka vi kan karakterisera en Generativ AI:s uttrycksförmåga? Jag har hittat mycket lite arbete kring detta, största delen av studierna kring egenskaper och förmågor hos en Generativ AI sker via olika typer av experiment och via empiriska undersökningar av dessa program. En AI kan inte heller förklara sig, dvs. den är ett helt eget forskningssområde (Explainable AI), där man försöker ta fram metoder som kunde bättre förklara varför AI:n kommer fram till en viss slutsats. Så länge det här problemet inte är löst ser jag mig ovillig att styras av en AI. Det här är också grunden till varför EU:s nya AI reglemente i praktiken gör det omöjligt att använda AI för t.ex. automatiserat beslutsfattande.
Ovan gick jag igenom vissa frågeställningar som jag upplever är viktiga att vara medveten om då det gäller AI. På grund av dessa kommer jag att uppdatera min kurs för hösten 2024, och försöka ta en mycket mera kristisk och diskuterande ansats till ämnet.
- Why data is the new oil | FutureScot↩︎
- Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’21). Association for Computing Machinery, New York, NY, USA, 610–623. https://doi.org/10.1145/3442188.3445922↩︎
- Gary Marcus analyserar i sin blog Diving deep into OpenAI’s new study on LLM’s and bioweapons den statistiska analys som OpenAI (Microsoft) gör i sin publikation där de hävdar att risken att kunna använda Chat-GPT för att utveckla biovapen är liten. Marcus analys visar att OpenAI använder sig av dubiösa metoder för att försköna resultaten, och att man likväl kan tolka resultaten i fullständigt motsats, dvs att Chat-GPT de-facto kan hjälpa en potentiell terrorist att skapa bio-vapen.↩︎
- Is AlphaGeometry a dead end? – by Michael Harris visar på flera problem med DeepMinds (Google) AlphaGeometry, där man blandar ihop matematiska upptäckter (matematik är egentligen en experimentel vetenskap, läs t.ex. Imre Lakatos “Proofs and Refutations”), resonemang och förståelse.↩︎
- Is AlphaGeometry a dead end? – by Michael Harris↩︎
- Nvidia’s H100 GPUs will consume more power than some countries | Tom’s Hardware↩︎
- TESCREALism: The Acronym Behind Our Wildest AI Dreams and Nightmares↩︎
- Accelerationism – Wikipedia↩︎
- openai will use 10 million nvidia gpus to create an advanced ai model – blog↩︎