

 “When you can measure what you are talking about
“When you can measure what you are talking about
and express it in numbers, you know something about it”.
Lord Kelvin, 1824-1907
I ett tidigare inlägg här i forskarbloggen berättade jag att jag nu jobbar som post doc forskare vid University of Wolverhampton (Go Wolves!). Jag jobbar i ett projekt där vi analyserar den vetenskapliga komunikationen på Twitter och bl.a. kartlägger informationens spridning över nätverk. Metoderna som vi använder kan enkelt används för andra ändamål också och av en del av dessa tänkte jag lite skriva om nu.
Den sociala webben är en enorm informationskälla där man relativt enkelt kan samla in mänskors åsikter, tankar och diskussioner. I princip kan man samla allt vad mänskorna skriver på webben. Det finns speciellt för akademiskt ändamål designade web crawlers som kan under en viss tid samla inlägg från givna rss flöden från t.ex. bloggar eller olika diskussionsforum. Twitters api tillåter att man kan begränsat samla in meddelanden som mänskorna skriver där. Twitter har faktiskt blivit en guldgruva för forskning, både marknadsforskning men även forskning om vetenskaplig kommunikation, informationens spridning, mänskors åsikter om olika saker, osv. osv. Man använda Twitter meddelanden för att analysera vad mänskorna tycker om olika produkter, brand, vetenskapliga artiklar, upptäckter, forskning, etc. Om man inte har tillgång till verktyg som samlar in meddelanden från t.ex. Twitter så kan man också köpa meddelanden. Till exempel företaget Gnip är en mellanhand som säljer material från Twitter och många andra sociala medier. Hälften av alla meddelanden under ett års tid från Twitter får man köpa för ett sexsiffrigt tal, och det är också massor med företag som köper (eller samlar själv) materialet för att undersöka vad mänskorna skriver om dem och deras konkurrenter.
I slutet av 2011 skickades ca 250 miljoner meddelanden på Twitter varje dag, så om man samlar ens en bråkdel av detta (vilket man är tvungen till eftersom Twitter begränsar antalet meddelanden som man genom deras api kan samla in) så behöver man a) program som klarar av att hantera denna s.k. big data, och b) datorer som klarar av att utföra de nödvändiga operationerna inom rimlig tid. Att indexera några hundratusen meddelanden kan med en ”normal” bordsdator ta en dag eller två, så med moderna tablet datorer och notebooks kan man helt glömma bort.
Vad kan man sedan göra med all denna data man samlat in? För det första måste man komma ihåg att så gott som allt material som man samlar in på webben innehåller en massa skräp. Om man t.ex. samlar in meddelanden som nämner Apple för att analysera Apples (företagets) synlighet på webben så får man garanterat även meddelanden som handlar om äppelpaj (apple pie). Så utmaningen är att få fram det som är värdefullt, få fram signalerna som indikerar något intressant, från den enorma mängden av meddelanden.
För det aktuella projektet har jag hittills samlat in över en miljon meddelanden från Twitter. Genom att under ett par månaders tid samla in meddelanden som innehållit vissa ämnes- och forskningspsecifika termer samt meddelanden som forskare inom vissa ämnen skrivit, har vi nu en mängd meddelanden som borde innehålla vetenskaplig kommunikation. Men som en snabb analys visar så innehåller materialet även en hel del s.k. false positives, dvs positiva träffar men som inte sen heller innehåller det man varit ute efter att samla. Det kan vara t.ex. ord eller förkortningar som använts i olika meningar eller på olika språk.
Ett sätt att hitta det mest intressanta från en mängd meddelanden är att mäta ordfrekvenser. Ett enkelt sätt är att kopiera texterna eller rss flödet in i Wordle, som ger ett ”ordmoln” med ordfrekvenserna. Man kunde t.ex. direkt mata in flödet från en viss blogg eller spalt i ett diskussionsforum och få en översikt om vad diskuteras. Ett annat sätt att analysera data är att göra tidsserier. Man mäter då frekvenserna som vissa ord använts under en viss tid för att se om det hänt något överraskande som plötsligt fått mänskorna att diskutera och kommentera ämnet i fråga. Drömmen för en forskare (och säkert även journalister) skulle ju vara att upptäck en motsvarande frekvensökning i diskussionerna före ämnet som diskuteras hunnit bli en nyhet i traditionell media. Med andra ord att hitta nyheterna före det blir nyheter. Från ordfrekvenserna kan man alltså se de mest använda orden, som man sedan kan använda för tidsserier för att se när dessa ord använts. Man kan då också plocka ut de meddelanden där ordet i fråga har använts för att göra ytterligare innehållsanalys på materialet.
För bilderna nedan har jag använt ca 60 000 meddelanden som forskare inom ’astrophysics’ har skrivit under ett par månaders tid. Jag använder denna data för att lite demonstrera vad som är möjligt att göra. I bilden nedan kan man se en lista på alla meddelanden i den data som jag nyligen samlat som innehåller ordet *mars*. Man kan också se hur mars kan handla om planeten mars eller om mars choklad. I nedre delen av bilden ser man hur begreppet *dark matter* har använts i Twitter meddelanden. Man kan tydligt se att mot slutet av data insamlingsperioden har det hänt något som fått mänskorna att tweeta mera om dark matter. Det har hänt något som ökat mänskornas intresse för detta. Men från denna bild vet vi då inte ännu om mänskorna är rädda eller oroliga för forskning om dark matter eller positivt inställda till nya upptäckter vid CERN. För att kunna säga något om det måste man kvalitativt analysera materialet. De tidiga topparna i datan är antagligen s.k. false positive, eventuellt spam. Nogrannare analys visar säkert om detta är fallet.
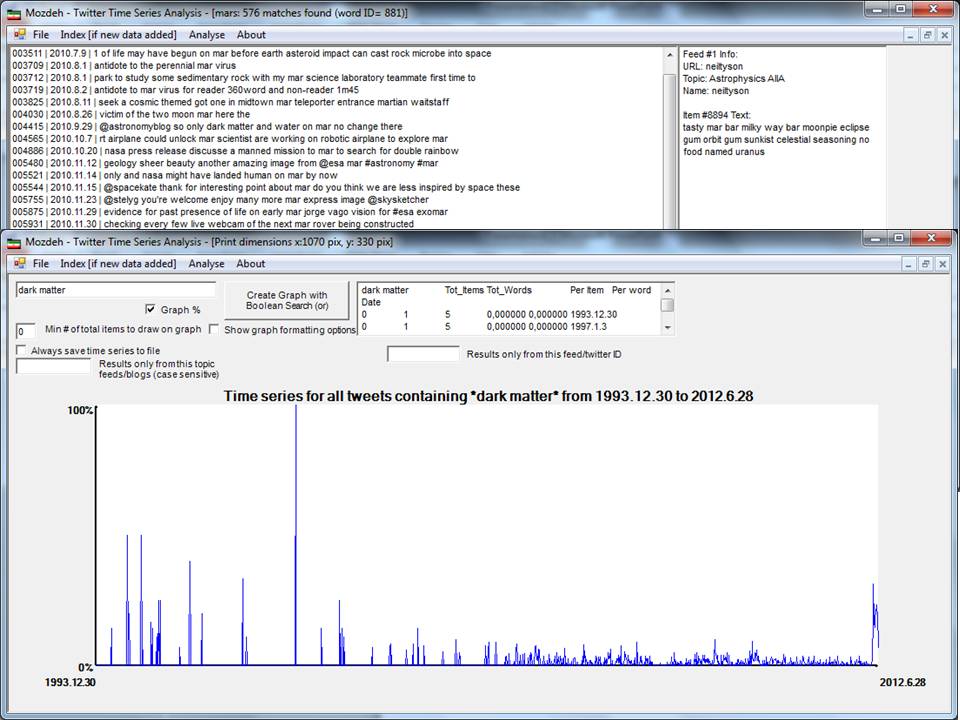
En annan sak som kan vara intressant att analysera är hur informationen spridits och via vem det spridits. T.ex. i forskning om marknadsföring kan det vara intressant att hitta personer som befinner sig i sådan position i sina sociala nätverk att de kan påverka en massa andra personer. Bilden nedan visar hur meddelanden som astrofysikerna skrivit spridit sig i deras sociala nätverk, med riktningen för meddelanden utsatt.
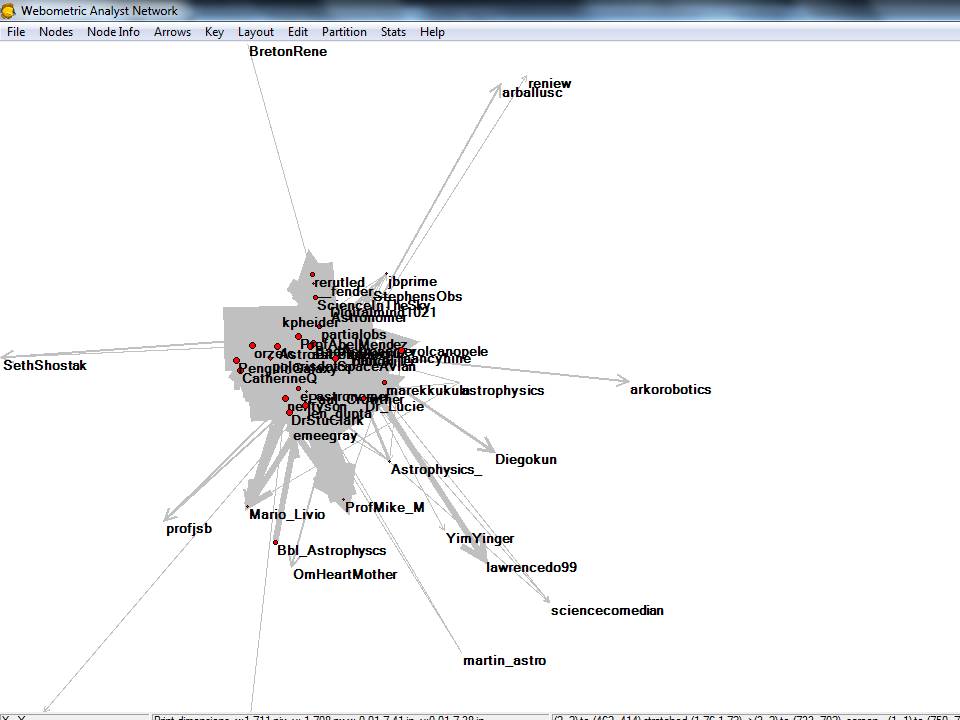
Nedan samma data med en annan visualisering, som jag personligen anser ge mera information. Grafen nedan är gjord med Pajek och Kamada-Kawai algoritm. Kamada-Kawai betraktar alla länkar som om de vore fjädrar mellan noderna (forskarna i det här fallet) som drar noderna närmare varandra tills det hittas balans mellan alla krafterna i nätverket.
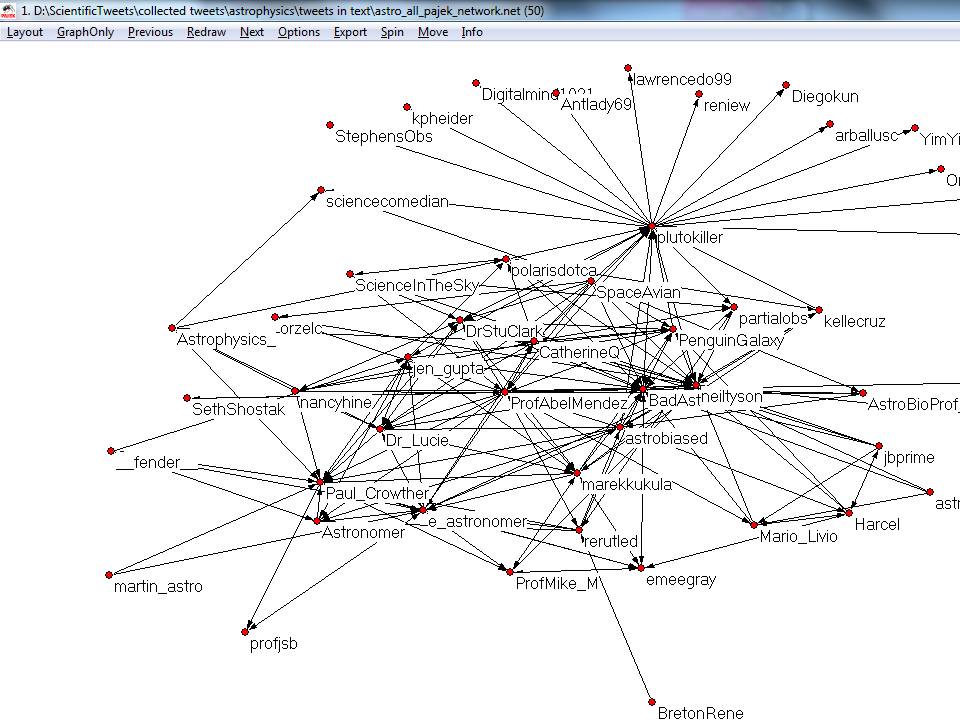 Man kan t.ex. se att Twitter användarna PlutoKiller, BadAstronomer och neiltyson är i såna positioner där de har inflytande på många andra personer, många andra som följer med vad de skriver. De har också en del inlänkar till sig, det vill säga personer som de följer, vilket gör att de också är i positioner där de har tillgång till ny information och nya idéer. Men från den första bilden kan vi se att åtminstone ett av meddelanden som neiltyson skickat handlade om Mars choklad, vilket väcker vissa misstankar. Närmare innehållsanalys krävs alltså.
Man kan t.ex. se att Twitter användarna PlutoKiller, BadAstronomer och neiltyson är i såna positioner där de har inflytande på många andra personer, många andra som följer med vad de skriver. De har också en del inlänkar till sig, det vill säga personer som de följer, vilket gör att de också är i positioner där de har tillgång till ny information och nya idéer. Men från den första bilden kan vi se att åtminstone ett av meddelanden som neiltyson skickat handlade om Mars choklad, vilket väcker vissa misstankar. Närmare innehållsanalys krävs alltså.
Det ska bli spännande att dyka djupare in i de ca 1 miljon Twitter meddelanden som vi har samlat hittills. Vem vet vad som döljer sig i data mängden.
Detta var mitt sista blogginlägg på ÅAs forskarblogg. I fortsättningen kan du följa med mina inlägg på http://kimholmberg.fi/. Inläggen där publiceras oregelbundet och sällan 🙂